
Prerequisites:
- Google Cloud Project with Big Query API Enabled.
- Google Service Account with Big Query User and Big Query Data Editor roles in your GCP project.
- Service Account JSON key to authenticate into your service account.
Set-up process:
Log in to your Datahash account on https://studio.datahash.com/login
Navigate to Warehouse category under Sources list in the left section.
Click on the “Google Big Query” connector tile.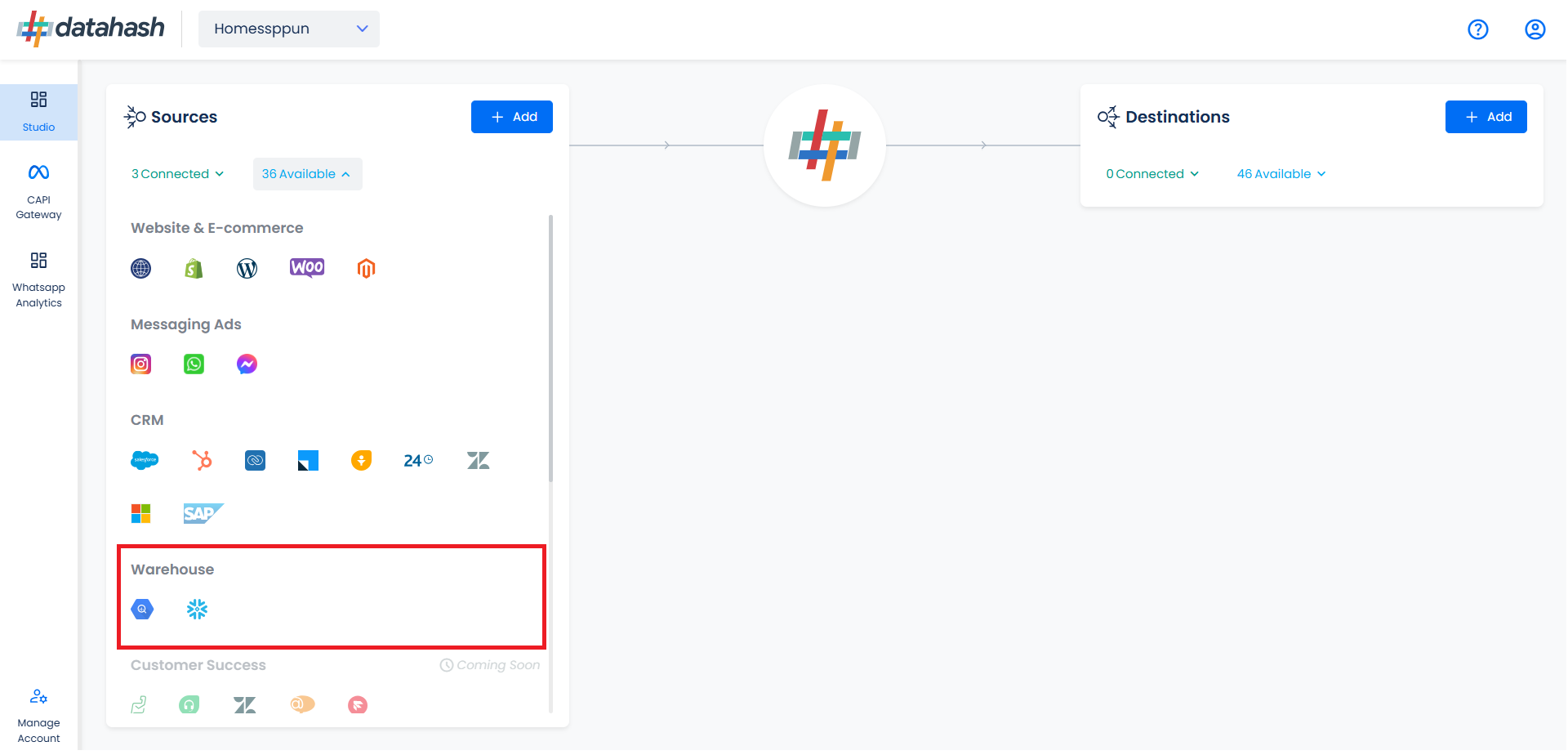
Choose the data entity as Snapchat Leads.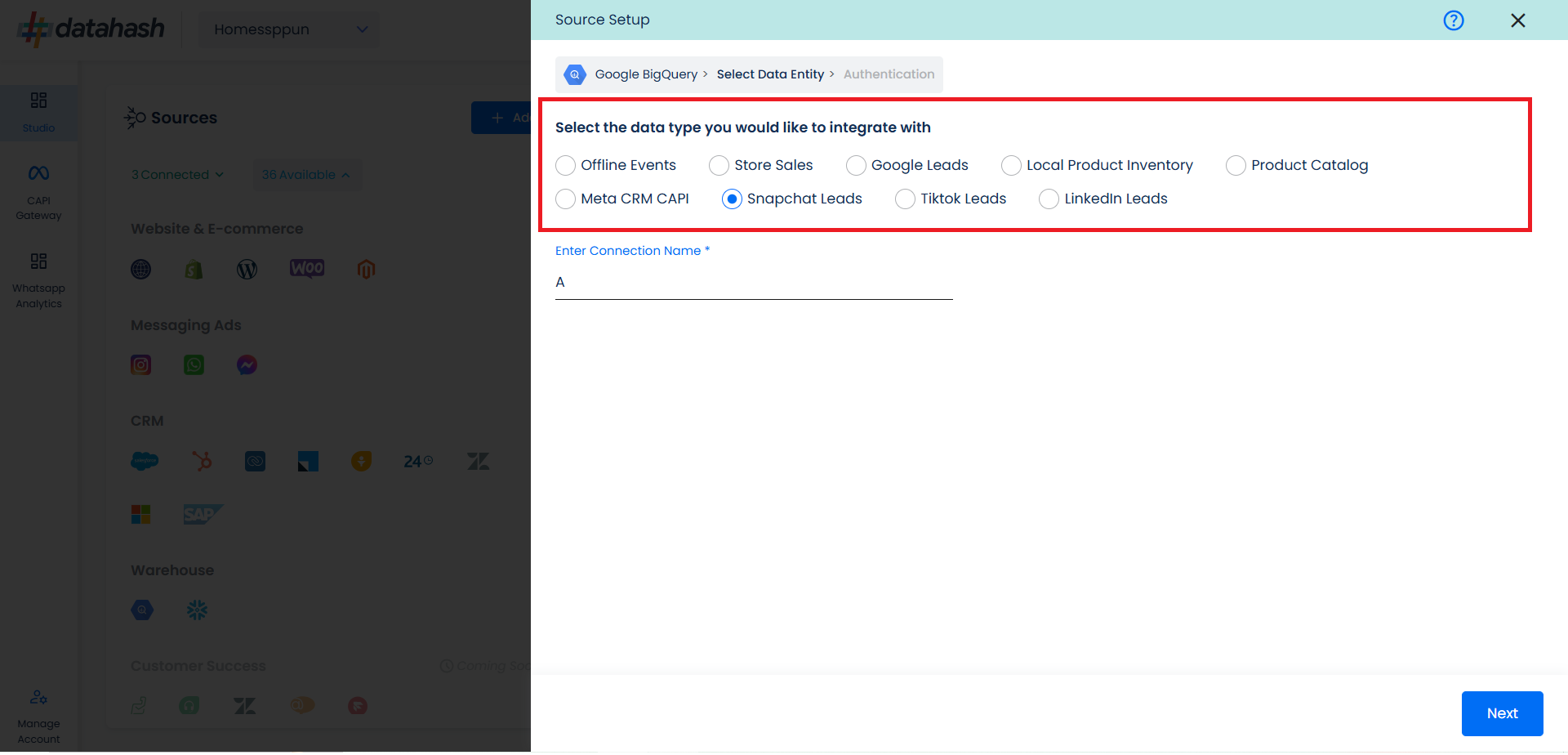
Once done, provide the connection name.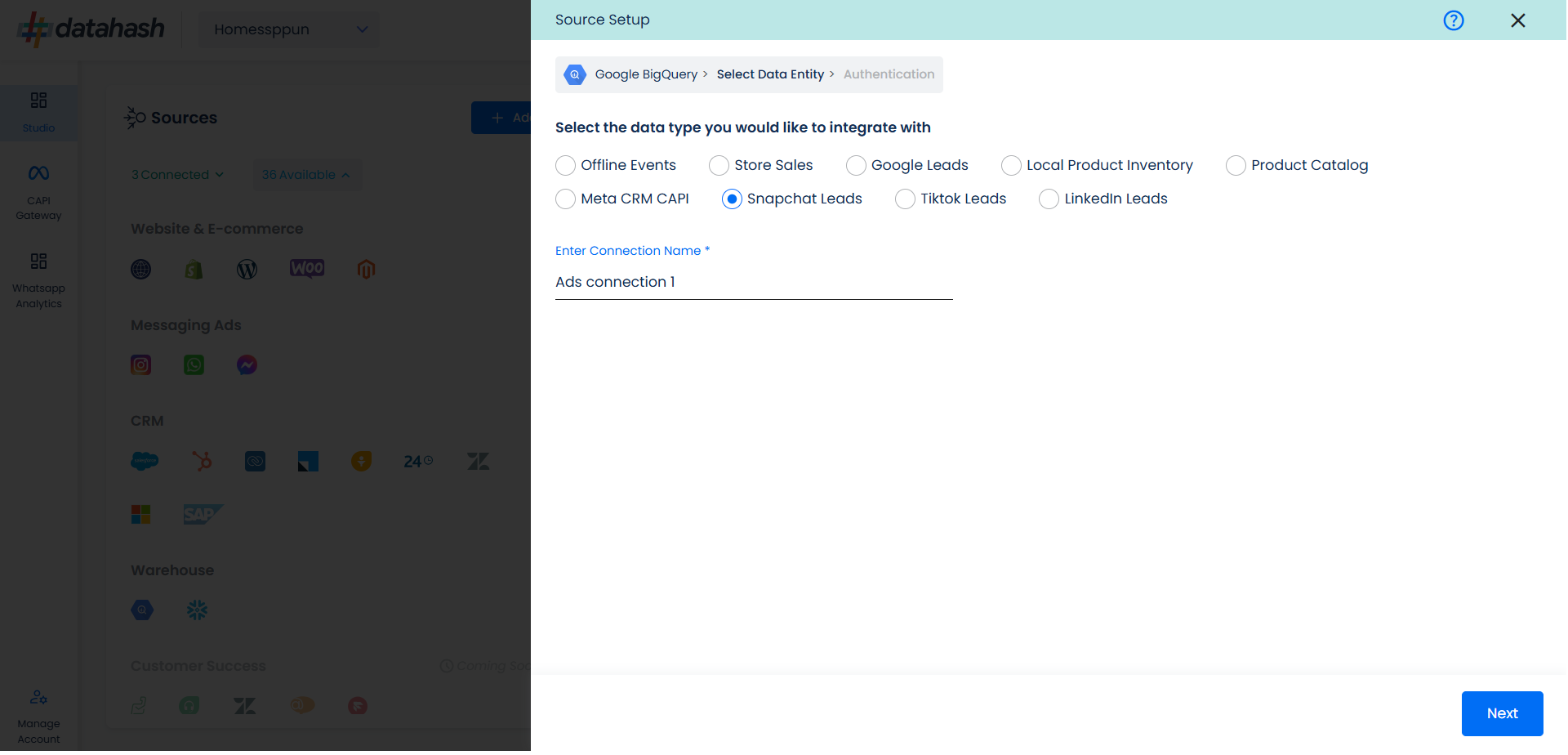
For this integration, click on “Snapchat Leads”. Provide a source name to your connection. Click Next.
There are 2 ways through which you can integrate, namely:
Table Path: Choose this if you would like to provide the data in a table format specified by Datahash
Query path: Choose this if you would like to provide the SQL query to Datahash through which data needs to be pulled.
For Table Path:
Table Name: Provide the table name from where the data needs to be extracted. It should be a part of your dataset ID provided.
In order to set up the connection successfully, kindly download the File Format, which helps you understand the overall structure in which you need to get the data setup.
The user needs to provide the Google cloud credentials, which will help Datahash to access the file for further processing. These credentials are:
JSON Key: A Google Cloud Platform (GCP) JSON key is a credential that allows a user to authenticate and access resources that a service account has been granted access to.
Project ID: GCP Project ID where your Big Query database is located.
Dataset Id: is a unique identifier for a dataset within a BigQuery project. A dataset is a container that holds tables, views, and metadata for BigQuery. Provide the Dataset ID from which the data will be extracted.
Table Name: Provide the table name from where the data needs to be extracted. It should be a part of your dataset id provided.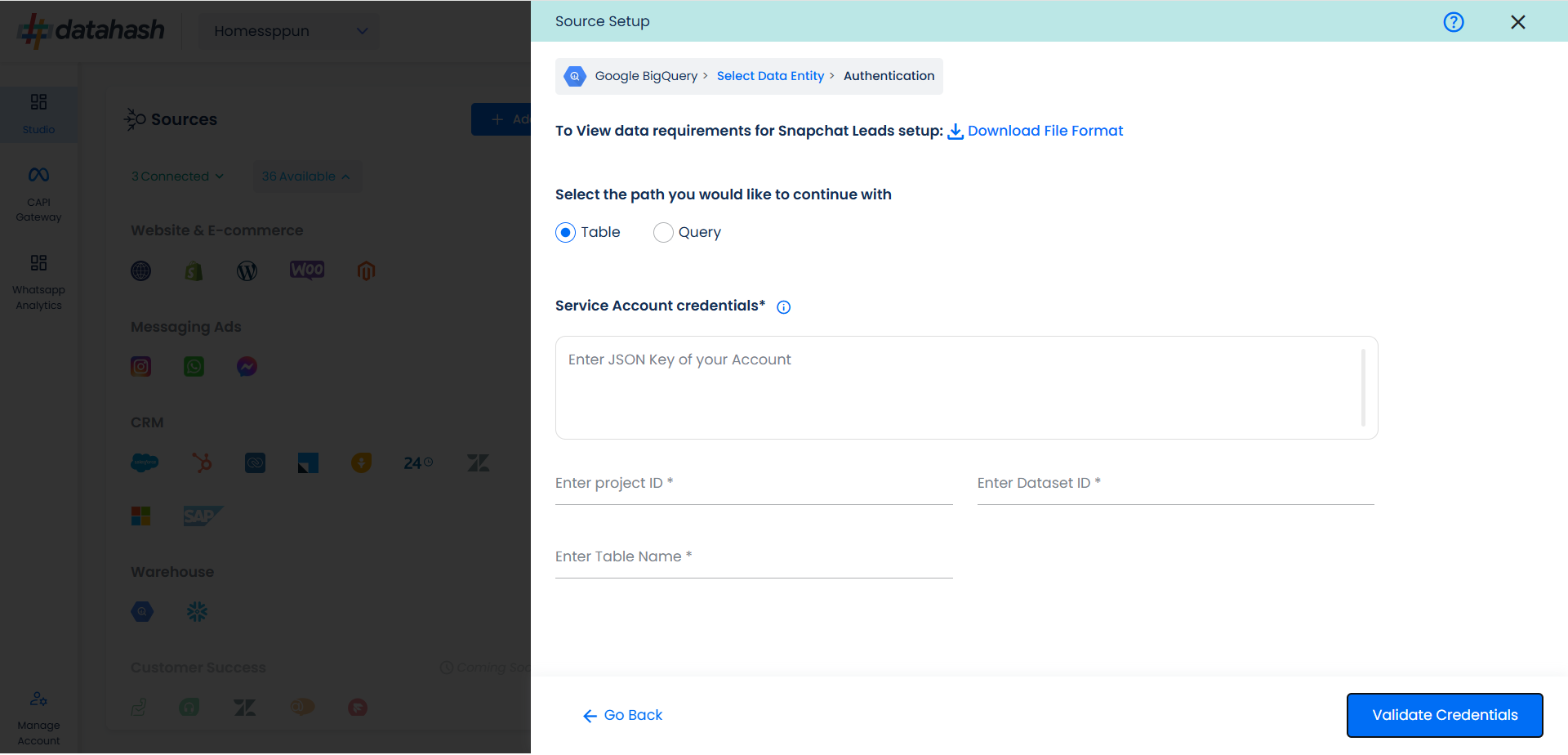
Once all the credentials are provided, click on Validate Credentials & Datahash will validate the credentials, after which the connection will be successfully set up – if all the credentials are valid.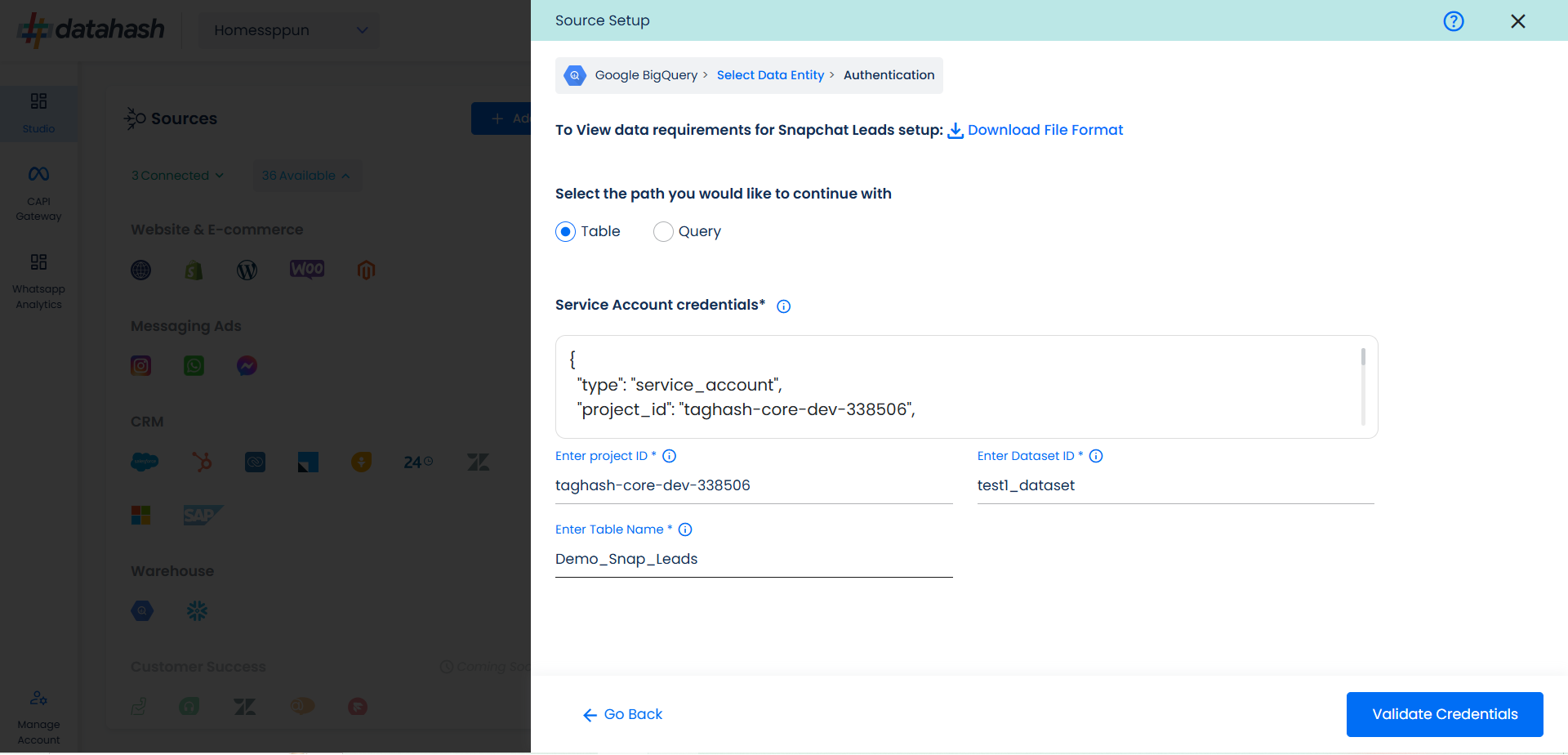
Click Finish to complete the setup.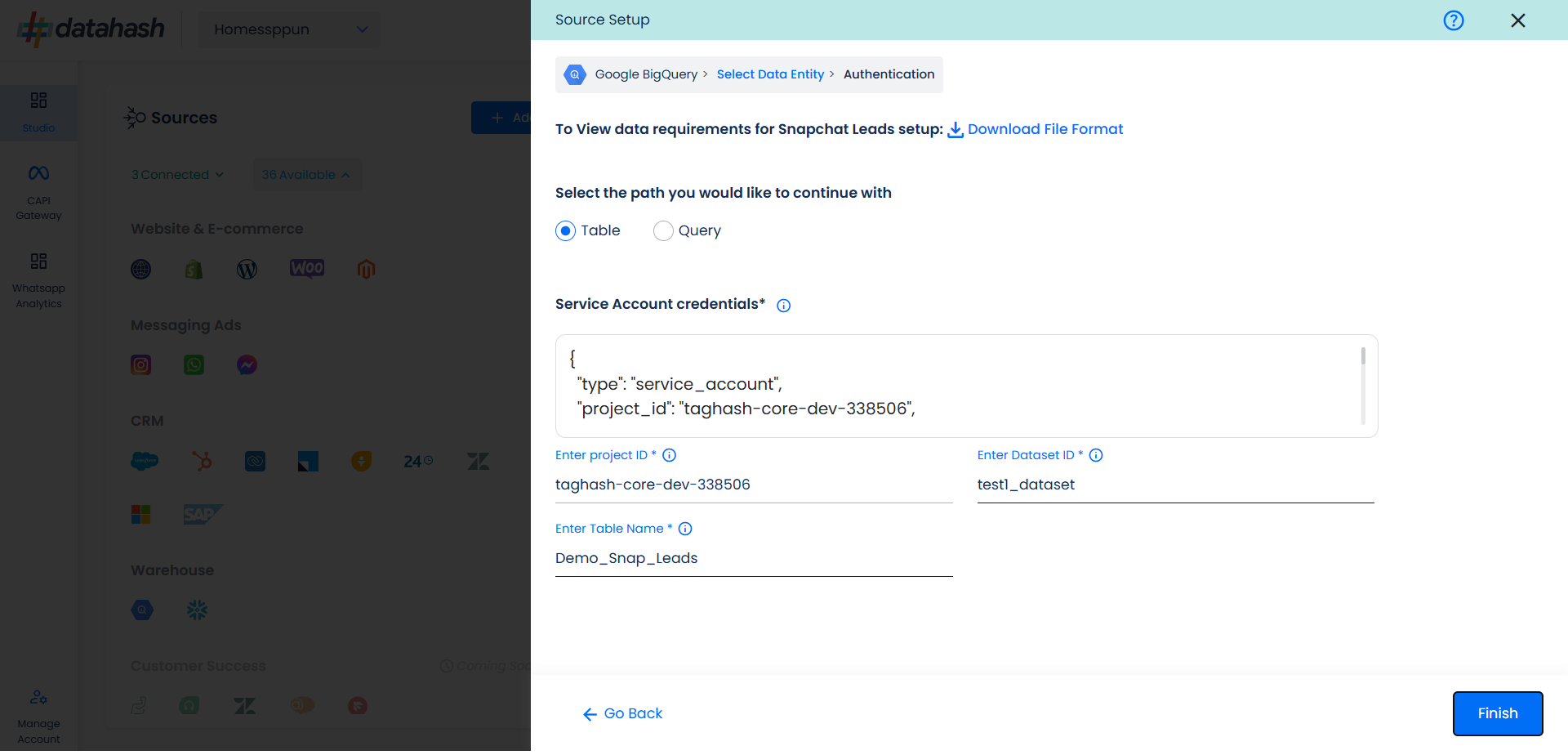
For Query Path:
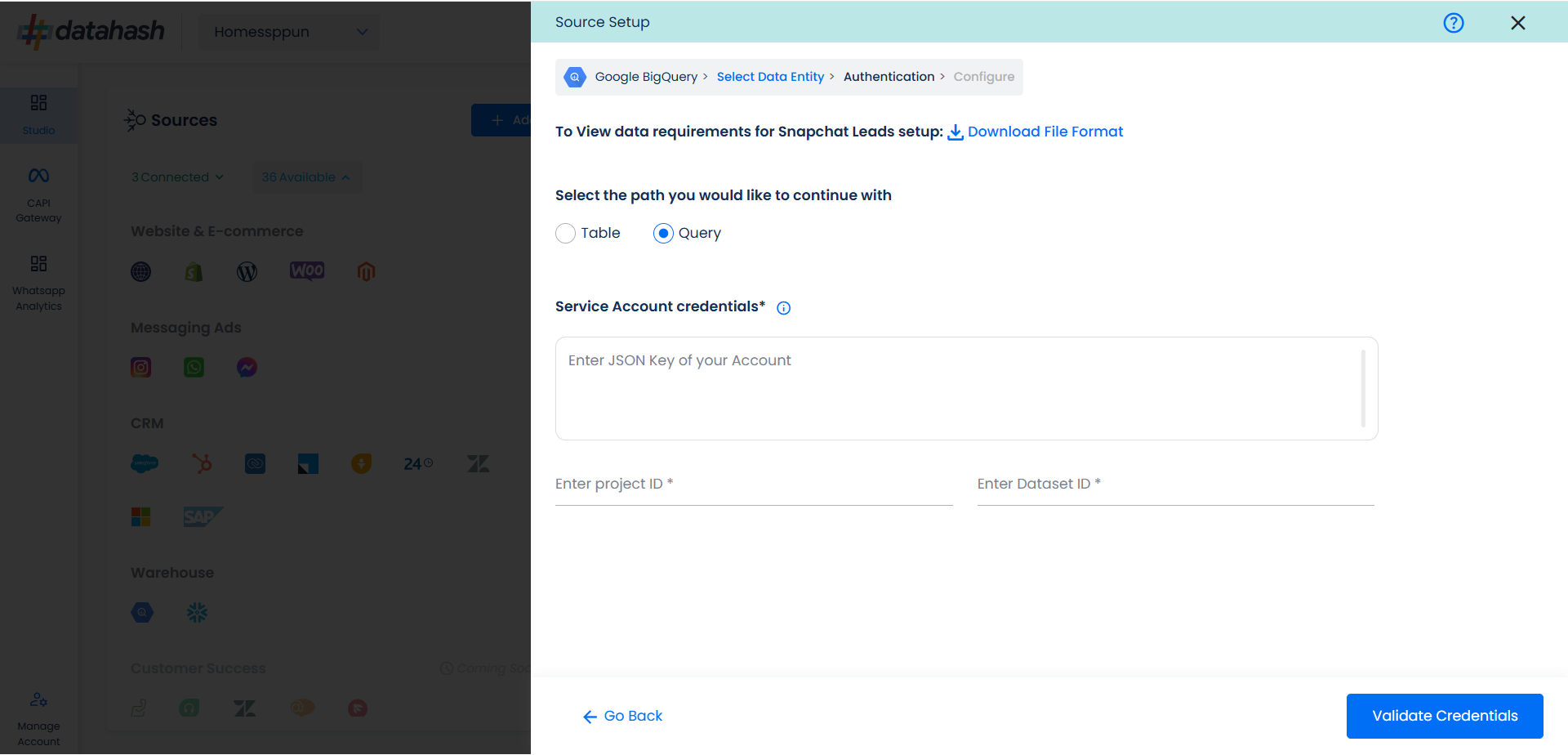
The only difference between query path and table path for authentication is that the table name is not asked in the Query path since the same will be provided in the SQL query. The user needs to provide the below-mentioned credentials :
JSON Key: A Google Cloud Platform (GCP) JSON key is a credential that allows a user to authenticate and access resources that a service account has been granted access to.
Project ID: GCP Project ID where your Big Query database is located.
Dataset Id: is a unique identifier for a dataset within a BigQuery project. A dataset is a container that holds tables, views, and metadata for BigQuery. Provide the Dataset ID from which the data will be extracted.
Once done, click on Validate Credentials. Datahash will validate the credentials.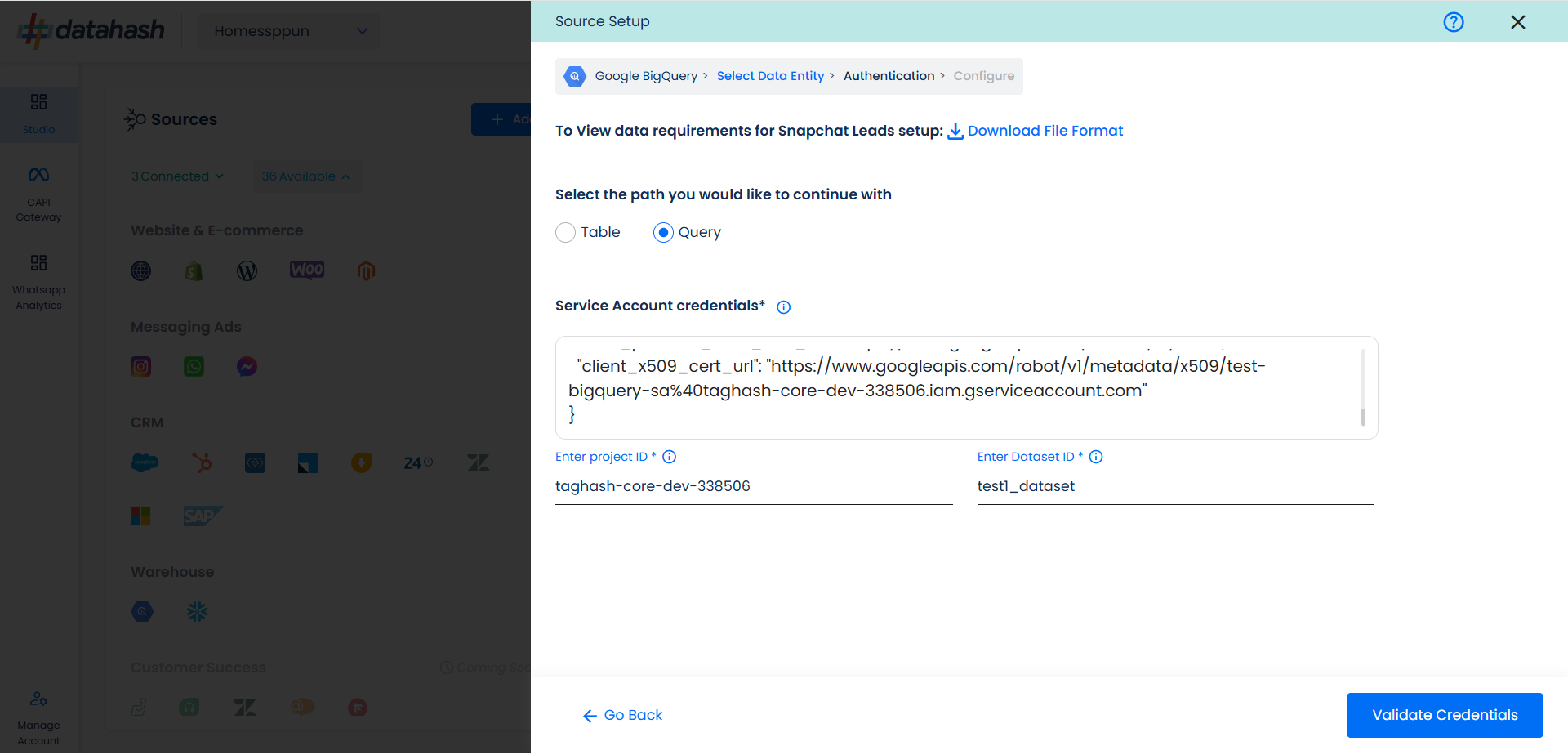
If all looks good, click Next to continue.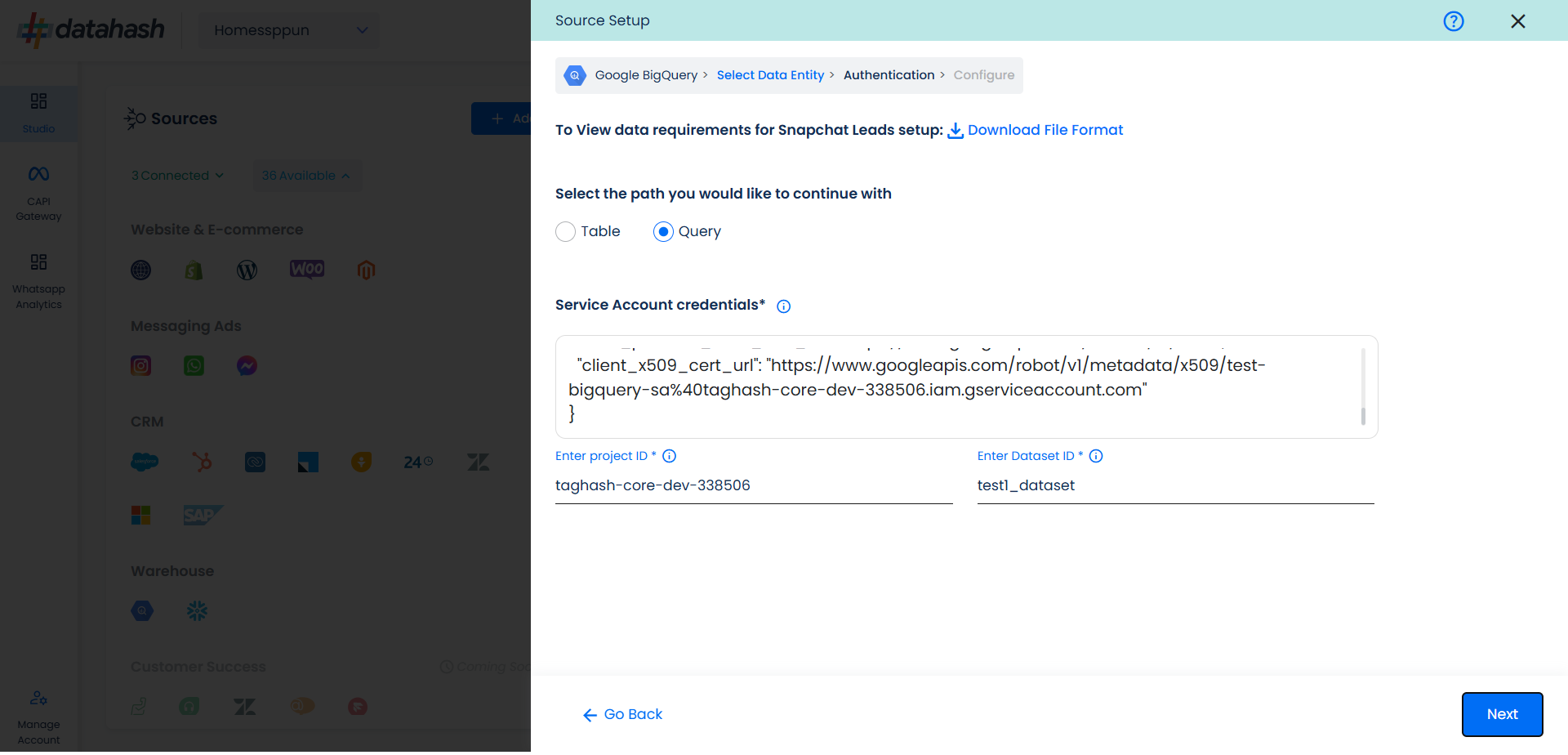
You will land on the “Configure” screen where you are required to provide the SQL Query through which you want Datahash to extract the data.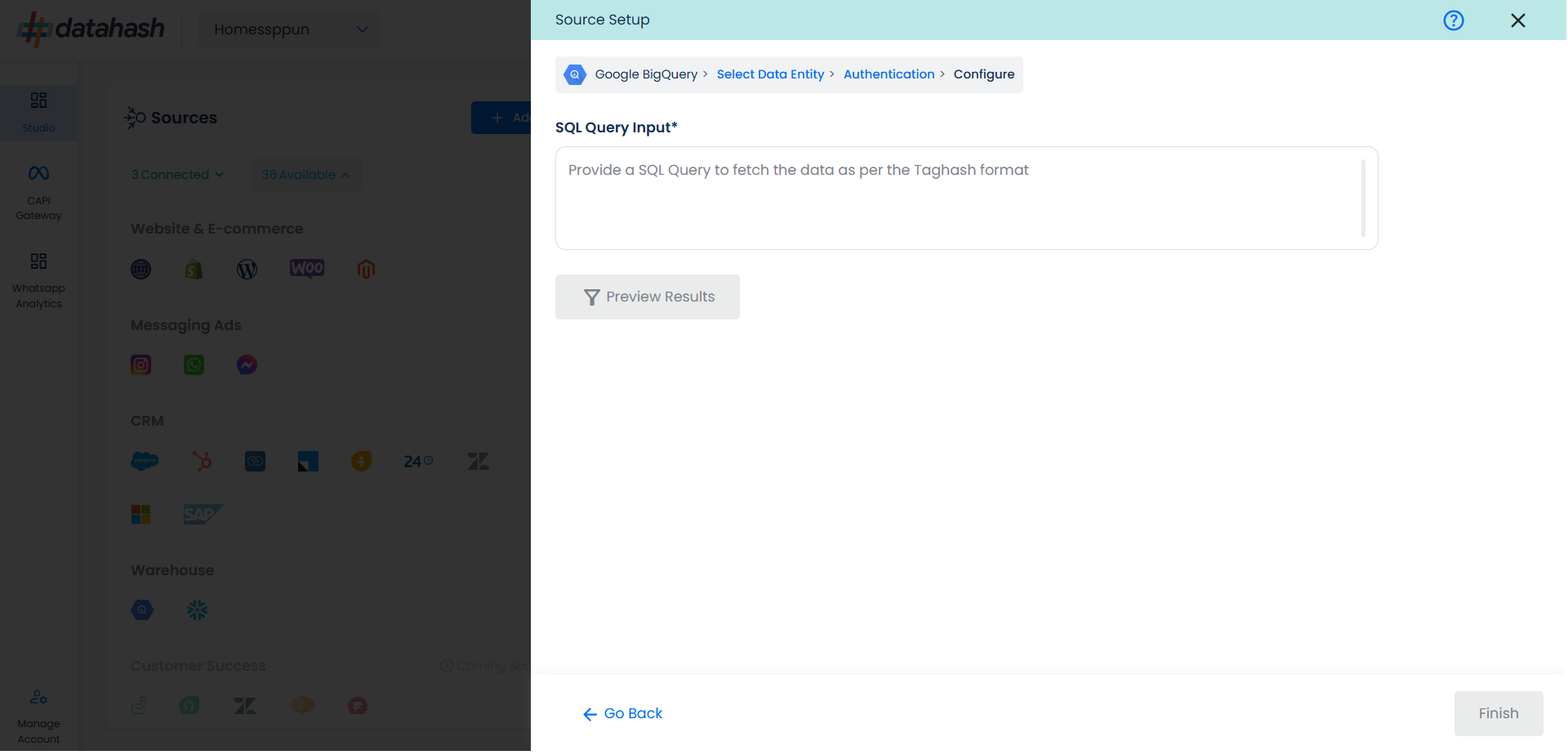
Once done, click on Preview Results.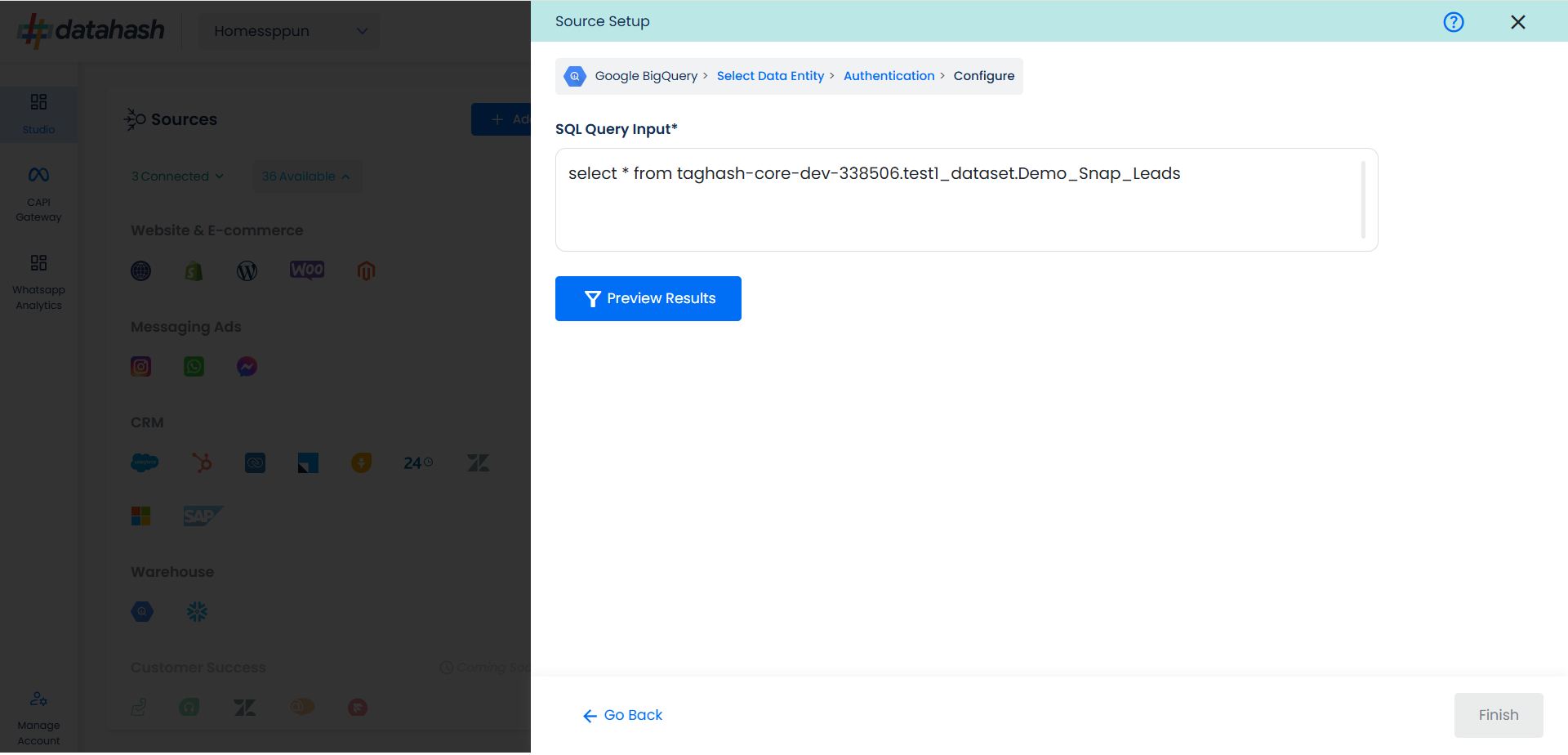
If everything looks good, click Finish to complete the setup. If the set-up is exited before finishing the set-up, the connector will remain in pending status and still be completed any time later by clicking the Connection Name in the below step.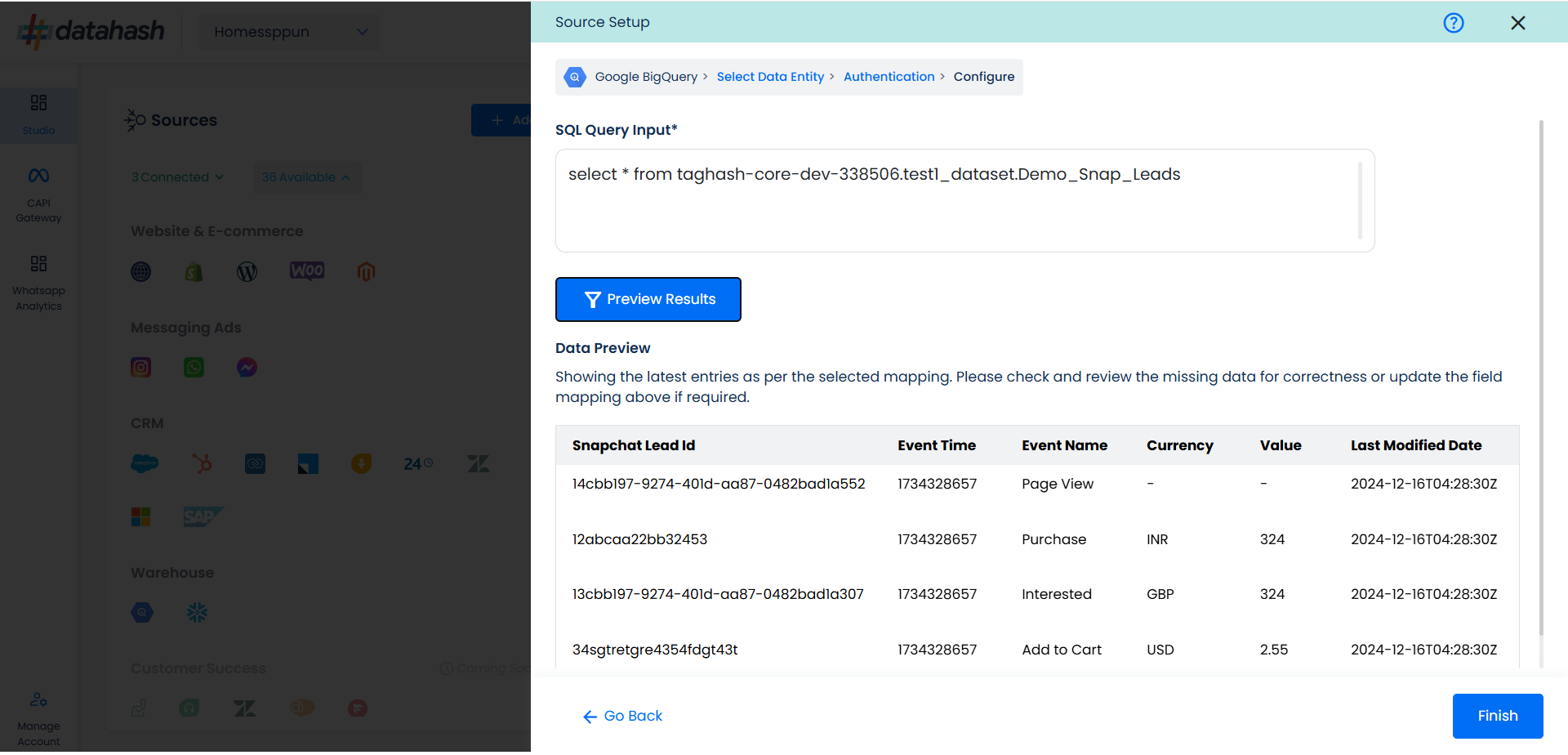
You can see the connected instance in the dashboard.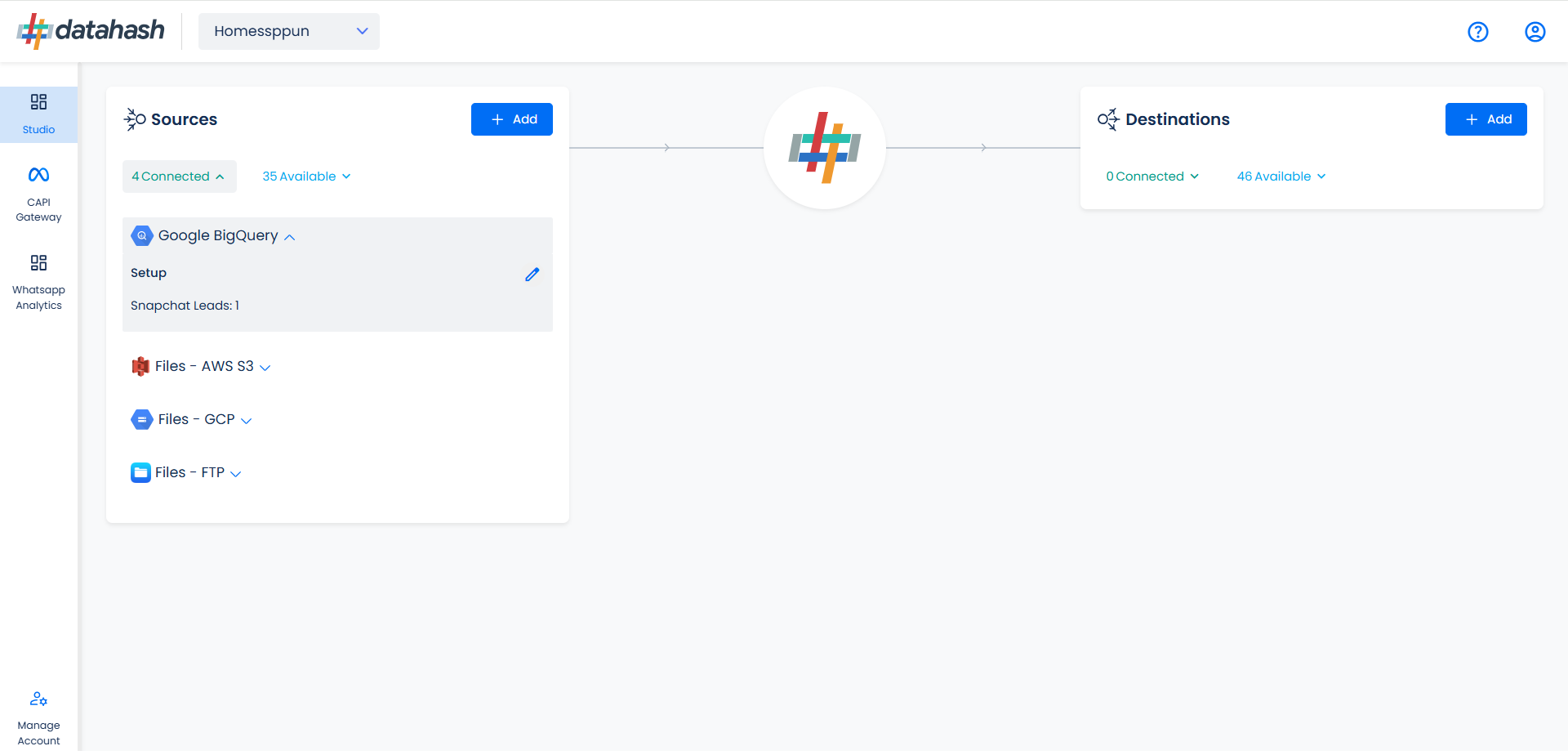
You can access the set-up again by clicking on the edit button in the Google Big Query connector widget.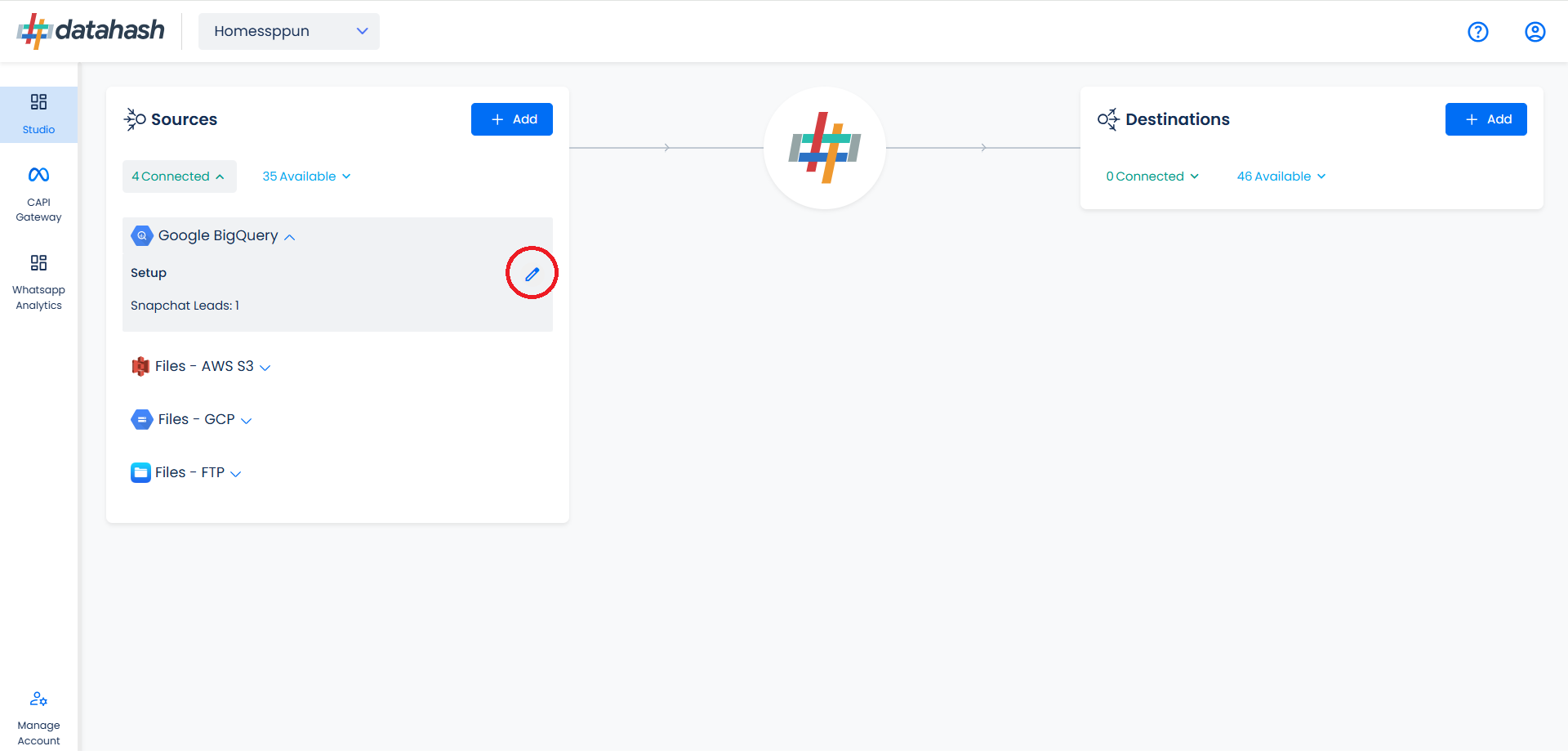
The set-up configurations from the Manage connections section can be edited if required.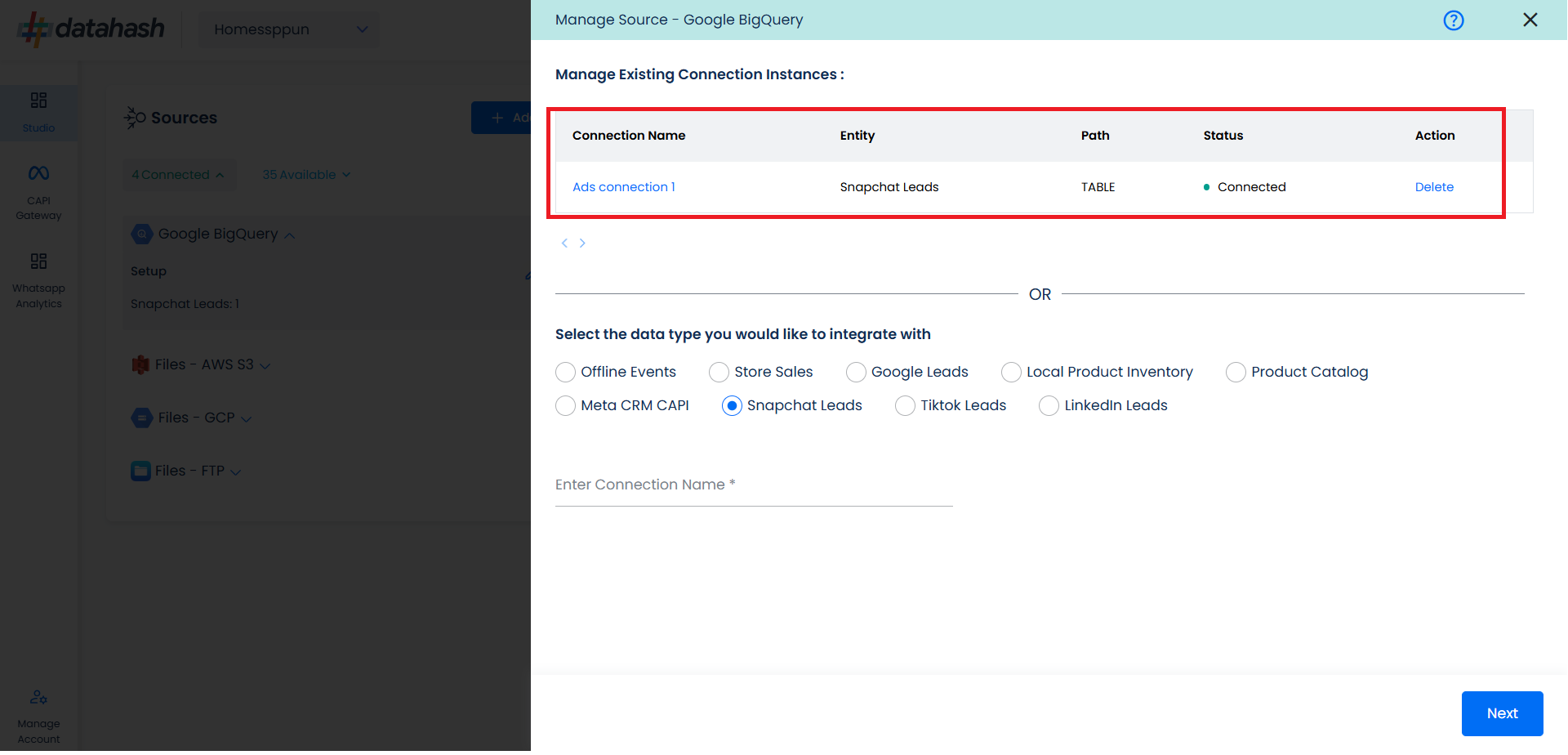
Getting the Credentials:
Go to Google Cloud & login to your account. On the top, click on the project.
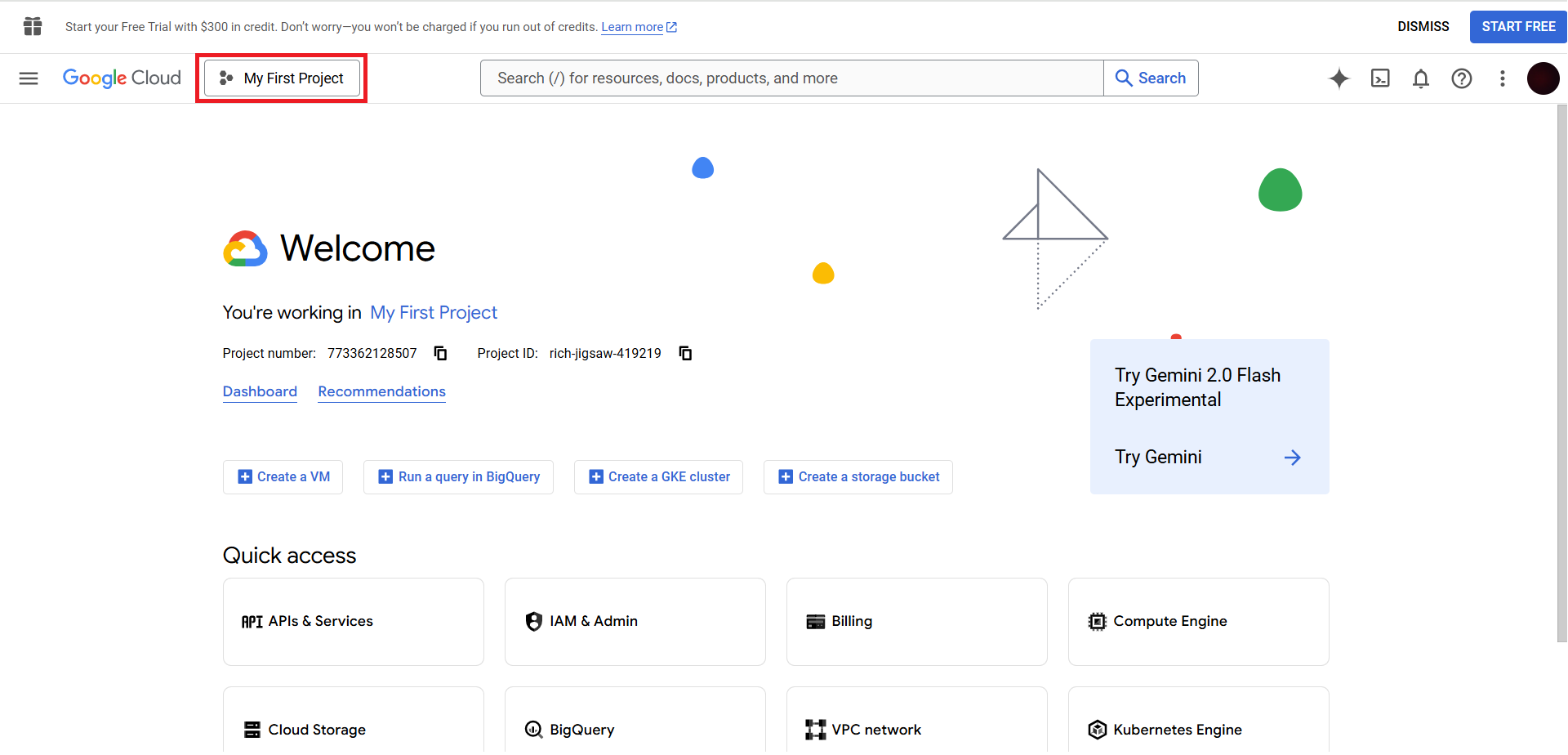
Here you can copy the Project ID.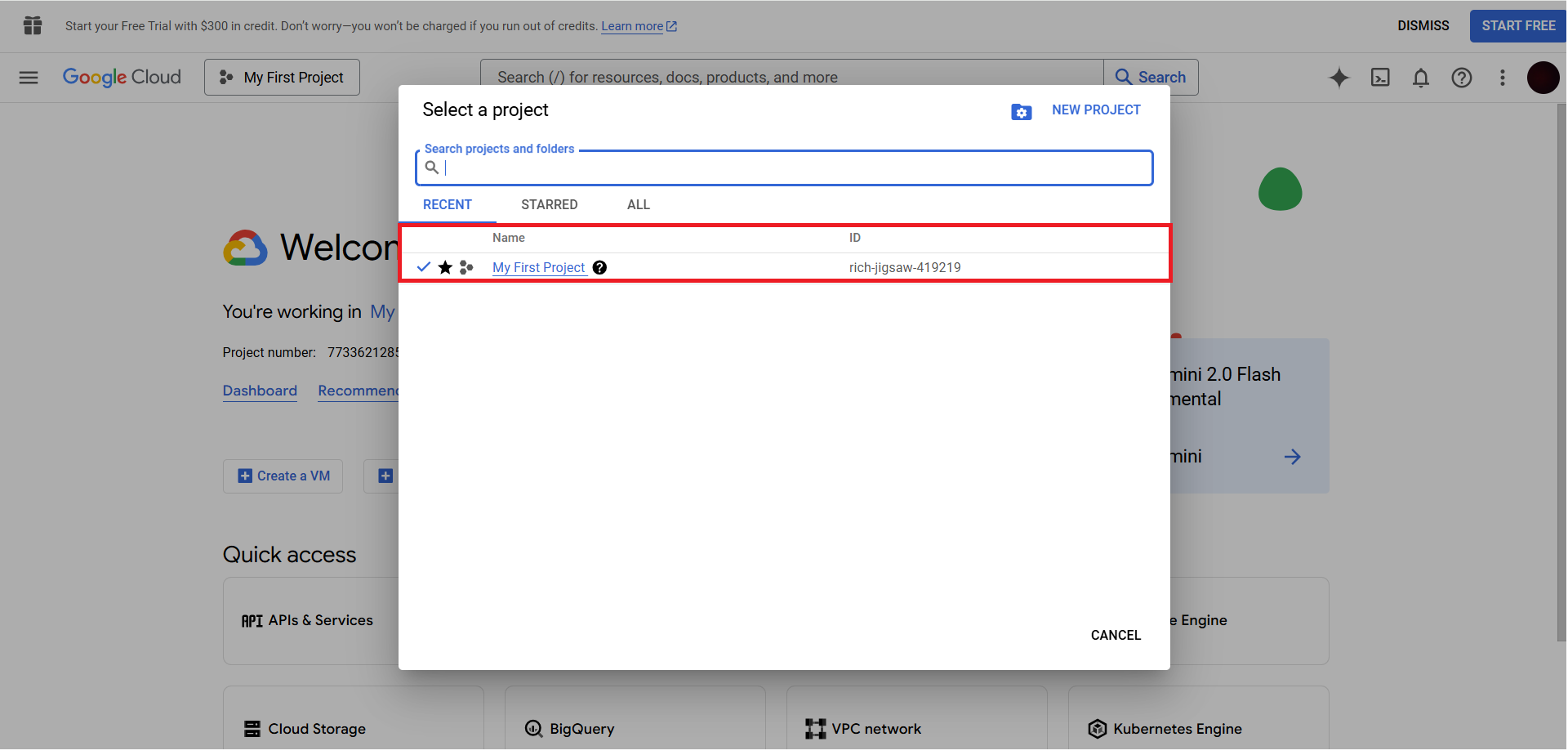
Once done, open menu & expand Big Query. Then click on Studio.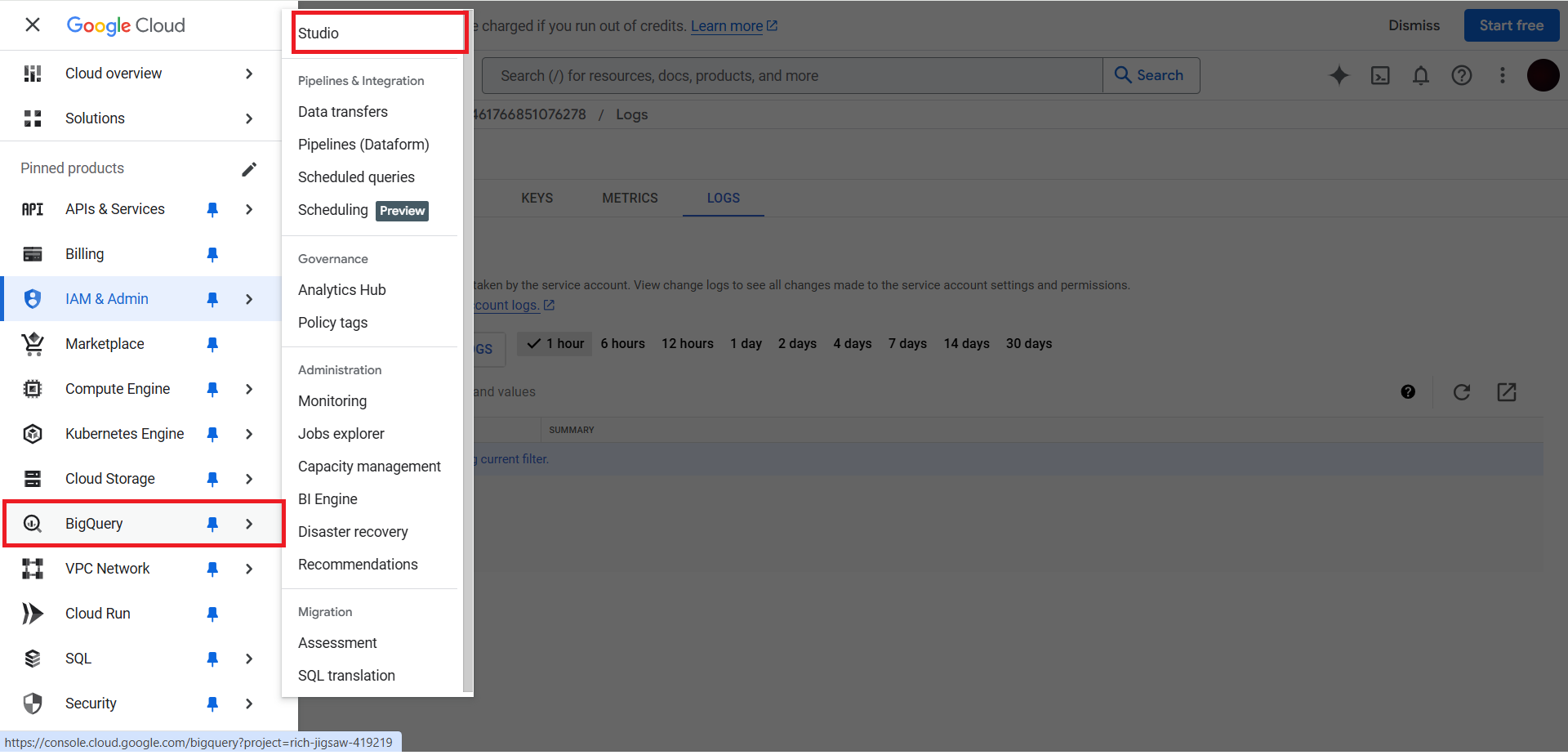
From the list choose the database. Under the database select the dataset & click on it. Here you can copy the Dataset ID.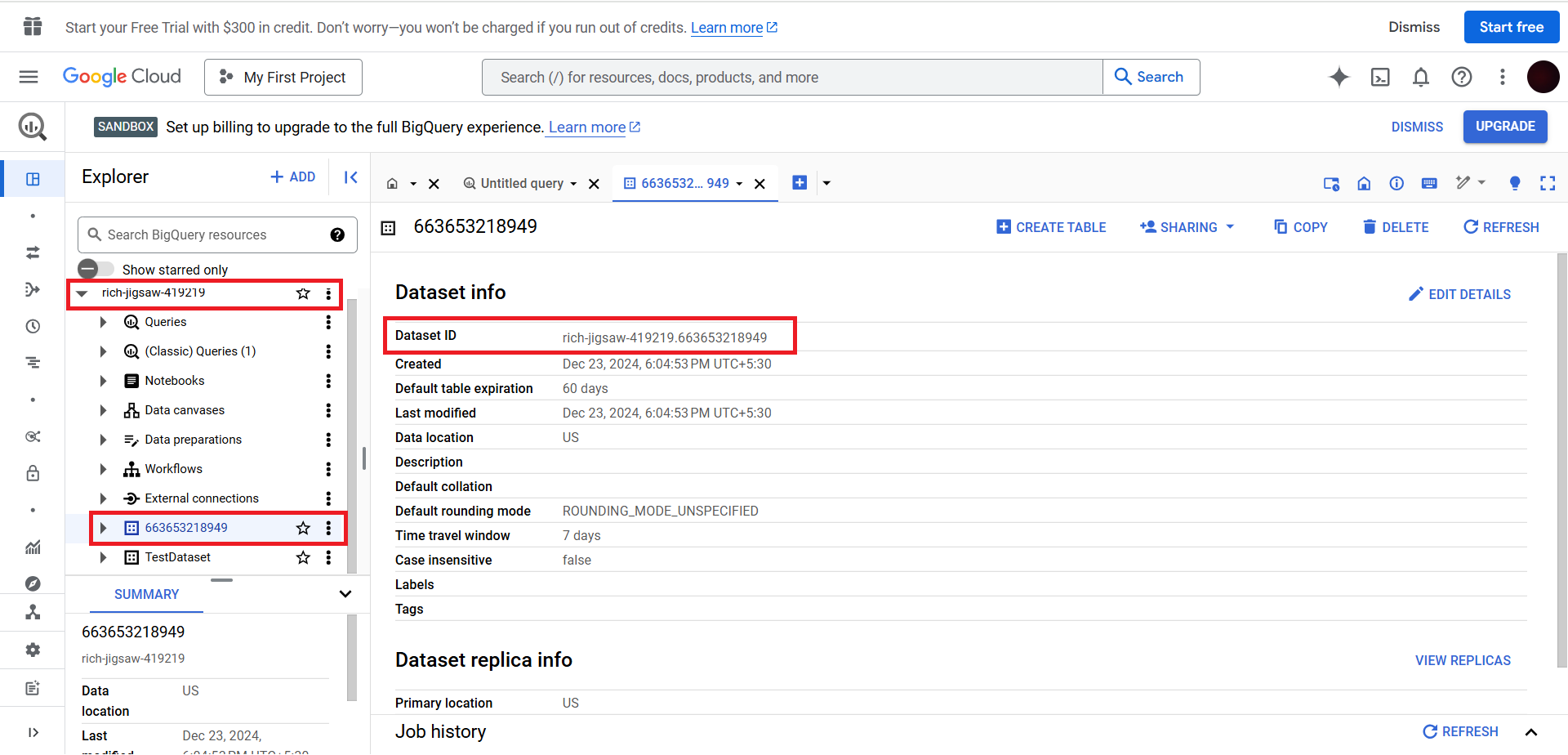
Once done, in the dataset choose the table & copy the table name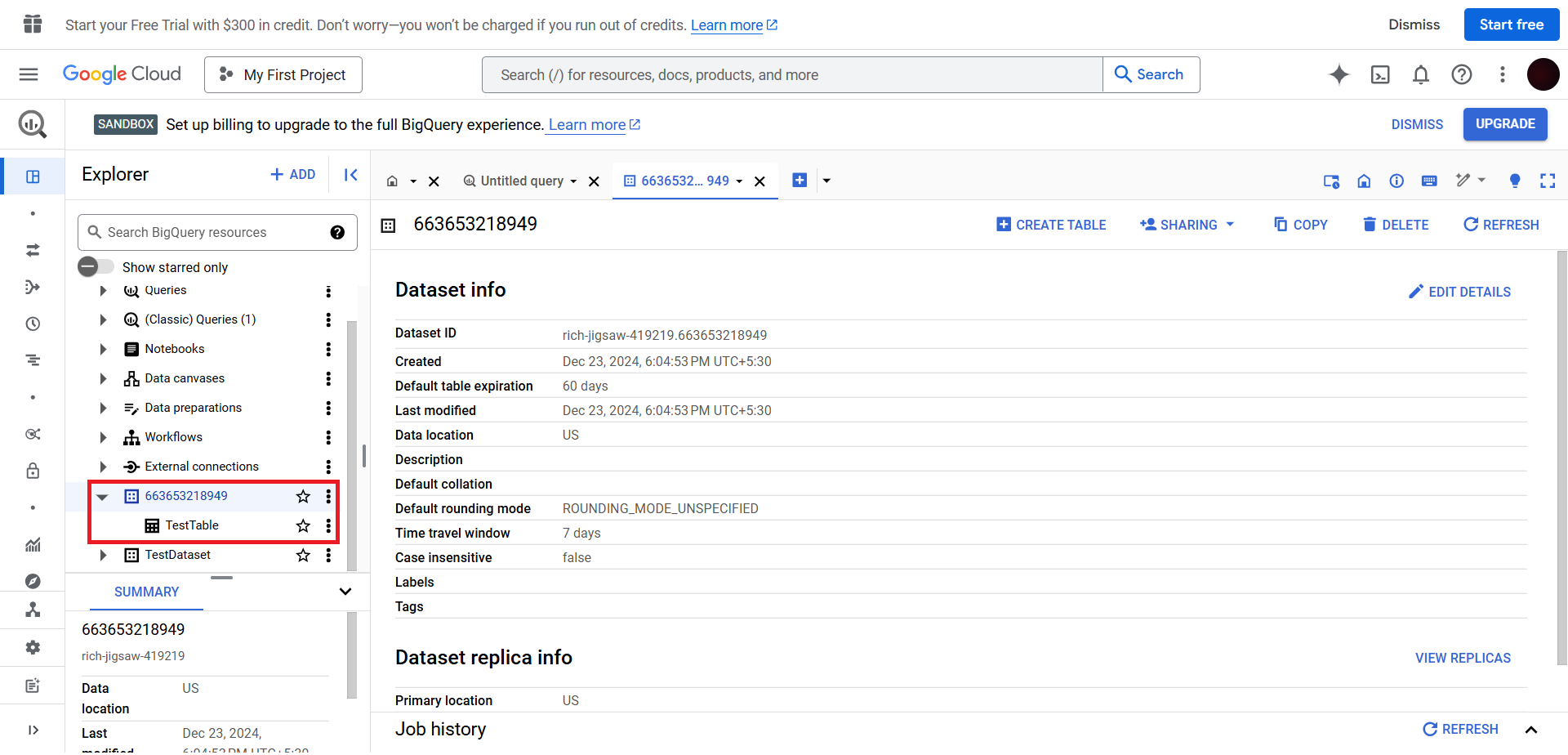
Once the setup is done once source, on the destination Snap Leads Conversions API is to be setup & you can refer the below link for it.
Step 2: Set up data destination for Snapchat Leads Conversions API – Datahash